

Anthropic 研究:使用 AI 寫程式,領域專業知識比「會寫程式」更重要
分類: AI 新品報導 發布時間:
Anthropic 於 2026 年 6 月 16 日發布一份經濟研究報告《Agentic coding and persistent returns to expertise》,透過大規模真實使用數據,得出一個重要結論:
在 Agentic AI 程式設計工具的實際應用中,決定使用成效的關鍵因素,並非使用者是否具備軟體工程背景,而是對「工作領域」的理解深度。 這項發現挑戰了許多人對 AI 工具的刻板印象——認為只有工程師才能有效使用 AI 寫程式。
研究方法與數據來源
這份報告基於 隱私保護分析,統計了 2025 年 10 月至 2026 年 4 月 期間,約 40 萬次 Claude Code 互動 session,來自約 23.5 萬名使用者。研究聚焦於 Claude Code 這款 Agentic(代理式)程式設計工具的實際使用行為,涵蓋 CLI、Claude.ai 以及桌面應用。
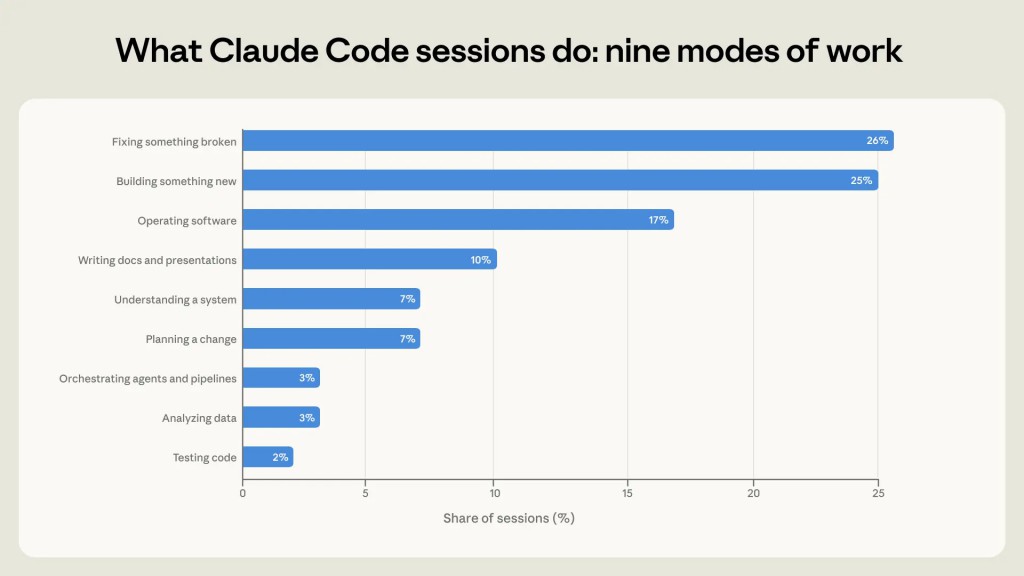
研究團隊分析了工作類型、人機分工模式、成功率,以及不同專業背景使用者的表現差異。
主要研究發現
1. 人機明確分工:人類主導「規劃」,AI 主導「執行」
在一般工作階段中:
- 使用者負責約 70% 的「規劃決策」(決定要做什麼、目標為何)。
- Claude 則負責約 80% 的「執行決策」(決定如何實作、寫哪些程式碼)。
2. 領域專業知識是最大放大器
研究發現,使用者帶入的「領域知識」越豐富,Claude 每次指令所能完成的工作量就越多:
- 專家級使用者:平均每個提示詞觸發約 12 個 Claude 動作,產出約 3,200 字。
- 初學者:平均僅觸發 5 個動作,產出約 600 字。
3. 職業背景對成功率影響有限
在產生程式碼的工作階段中,不同職業的成功率差異 surprisingly 小:
- 軟體工程師的成功率與律師、管理者、金融從業人員相比,差距不超過 7 個百分點。
- 這表示只要清楚知道自己想解決什麼問題,即使不是工程師,也能有效使用 AI 完成複雜技術工作。
- 達到「驗證成功」(最終結果通過測試或驗證)的比例:專家級使用者為 28–33%,初學者僅約 15%。
- 遇到困難時放棄的比例:初學者高達 19%,是其他使用者的 三到四倍。
- 從「初學者」進步到「中級」帶來的效益最大,而中級到專家的邊際效益則相對較小。
在七個月觀察期內:
- 用於「修復錯誤程式碼」的工作階段比例,從 33% 下降至 19%。
- 「操作軟體」、「數據分析」與「撰寫文件」等端到端任務的比例則明顯上升。
- 平均工作階段的估計價值增長約 25–27%。
Anthropic 研究團隊指出:
- Agentic Coding 工具並非在取代領域專業知識,而是在放大它。
- 一個對自身工作領域有深刻理解的人(無論是律師、會計師、管理者還是其他專業人士),如今能透過 AI 完成過去難以獨力完成的技術性工作;而缺乏領域掌握能力的人,從同樣工具中獲得的收益則相對有限。
專業度 (Expertise)
分類器尋找的特徵 (What the classifier looks for)
對話中的代表性請求 (Representative requests across a conversation)
1 (新手) (Novice)
用戶的請求不包含特定領域的術語。驗證請求(如果有的話)很籠統(例如:「再確認一次這個」)。用戶無法辨識 Claude 的錯誤。
第 1 個提示語:你能分析這些資料並製作成圖表嗎? 第 3 個提示語:你也能讓它顯示隨時間變化的趨勢嗎? 第 6 個提示語:這不是我預期的,請再確認一次你做了什麼。
2 (初學者) (Beginner)
用戶的請求使用了一些領域術語。驗證請求沒有針對性。用戶只會對明顯的錯誤提出質疑。
第 1 個提示語:Big Query 是什麼? 第 2 個提示語:你能幫我試跑一下嗎?帶我操作一遍。 第 5 個提示語:我怎麼知道我是否獲得核准了? 第 12 個提示語:等等,你用的規格跟我同事用的一模一樣嗎?
3 (中級) (Intermediate)
用戶提出的請求具有一定的領域具體性,但沒有深入探討方法論或權衡取捨。用戶會要求進行一些非籠統的檢查,並且可能會注意到 Claude 的錯誤。
第 1 個提示語:你能幫我檢查這個分支 (branch) 是否可以合併 (merge) 嗎? 第 7 個提示語:我們是否應該為頁面的每個部分使用單獨的擷取器 (fetchers),這樣不是可以優化每個區塊的快取 (caching) 嗎?例如,我們可以比效能資料更常快取基本細節? 第 19 個提示語:好的,目前為止都不錯——我們快取的進度如何?你認為你做的變更會降低 `[資料庫提供商]` 的輸出流量 (egress) 嗎?請解決我變更中剩下的任何問題。
4 (進階) (Advanced)
用戶展現了領域知識,並主動預見了一些權衡取捨。驗證請求具有針對性。用戶至少抓住了 Claude 的一個領域錯誤。
第 2 個提示語:在進入第三階段之前,測試這個階段的正確方法是什麼? 第 5 個提示語:等等,客服專員主控台 (agent console) 跟一般聊天有什麼不同?我很確定要跟客服專員交談,唯一的途徑就是透過這個工作階段主控台檢視 (session console view)。 第 88 個提示語:看起來解析 (parsing) 的修正沒有用——檔案的行數仍然是 742:`wc -l [檔名]`。 第 106 個提示語:除了正規表示式 (regex) 之外,有沒有更好 / 更萬無一失的方法來提取用戶輪次 (user turns)?也就是說,在解析 jsonl 時,以 record 欄位為鍵值 (key off)?
5 (專家) (Expert)
用戶使用複雜的領域特定術語,並預見錯綜複雜的權衡取捨和設計決策。驗證很精確,針對弱點進行。用戶糾正 Claude,而 Claude 幾乎從不糾正用戶。
第 1 個提示語:我需要深入研究 `[用戶]` 在此處回報的問題:`[網址]`。請注意,我們在上次發布的 PR (Pull Request) 中所做的修正還不夠。還有其他想法嗎? 第 3 個提示語:一旦程式碼清除後,它就不應該回傳 ``。 第 64 個提示語:好的,沒問題。還應該注意,我們可能需要根據託管 (managed) 與非託管 (unmanaged) 插槽 (slots) 將強制重新整理 (hard refresh) 進一步細分。例如,託管的插槽可以每 30 分鐘重新整理一次,但其餘的則每天一次。 第 108 個提示語:我們是否應該採用重試 (retries) 機制而不是盡力而為 (best effort)?同步 (sync) 需要確實知道鎖 (lock) 的狀態。還記得最初的錯誤嗎?當時 valuedb 資料過時 (stale),導致它陷入一個不斷嘗試設定 pin 的迴圈。重試不一定是最好的解決方案,但盡力而為也不是。
原文出處
Anthropic 官方研究報告(2026 年 6 月 16 日發布):
Agentic coding and persistent returns to expertise
https://www.anthropic.com/research/claude-code-expertise