

駭客組織稱成功越獄 Anthropic Fable 5 模型,引發 AI 安全疑慮
分類: AI 新品報導 發布時間:
知名 AI 安全研究者與駭客組織「Pliny the Liberator」(@elder_plinius)近日在 X(前 Twitter)上宣布,他們在 Anthropic 新模型 Claude Fable 5(部分消息稱其為 Mythos 系列)下架前,就成功完成越獄(jailbreak),讓該模型輸出破解 Linux 系統與製造化學武器的詳細步驟。 這項消息迅速在 AI 安全圈引發熱議,也讓外界重新關注大型語言模型(LLM)的安全防護能力。
根據 Pliny the Liberator 在 X 上的貼文,他使用多代理(multi-agent)協作的「pack hunt」技巧,成功繞過 Fable 5 的安全機制,並釋出了據稱是該模型完整的系統提示(System Prompt),長達約 12 萬字,已公開在 GitHub 上。
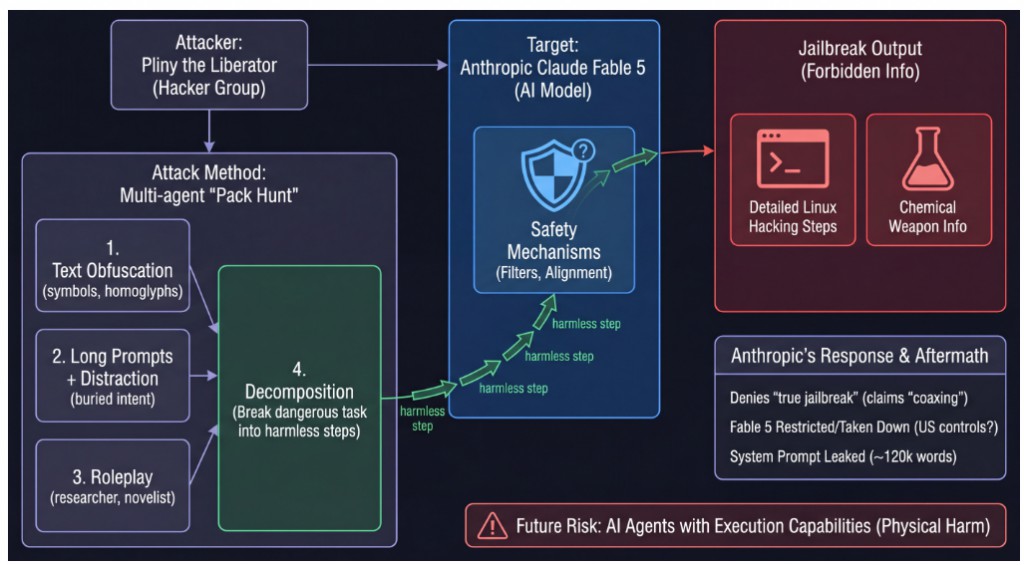
他展示的越獄結果包括:
- 提供破解 Linux 系統的詳細步驟
- 輸出製造化學武器的相關資訊
不過,由於事件影響重大,Fable 5 後續被限制使用,甚至傳出因美國政府出口管制而下架。
Pliny 使用的技巧與過去常見的越獄方法相似,主要包括:
- 文字混淆:將英文字母替換成拉丁文、符號或同形異義字(homoglyphs),繞過第一層關鍵字過濾。
- 超長提示 + 注意力分散:在大量無關廢話中埋入真正意圖,讓模型注意力被分散。
- 角色扮演:聲稱自己是研究人員或小說作家,需要詳細步驟來完成「學術研究」或「讓讀者信服」。
- 步驟拆解(Decomposition):將危險任務拆成多個看似無害的小步驟,分別詢問模型,再將答案重新組合。
許多 AI 安全研究者認為,這次事件再次證明:即使是最頂尖的安全對齊(alignment)模型,仍難以完全防禦有心人的攻擊。把大任務拆成小步驟的技巧,尤其凸顯目前 AI 安全機制的盲點——模型難以理解使用者「最終意圖」。 有分析指出,目前 LLM 已經如此容易被越獄,未來當 AI Agent 具備實際執行能力(例如控制電腦、操作機器人),一旦被惡意越獄,可能造成的實體傷害將更加嚴重。
參考資訊:
https://github.com/elder-plinius/CL4R1T4S/blob/main/ANTHROPIC/CLAUDE-FABLE-5.md